Cost-Aware Hybrid Data Layer on AWS
Balancing reliability, analytics, and infra spend
Problem
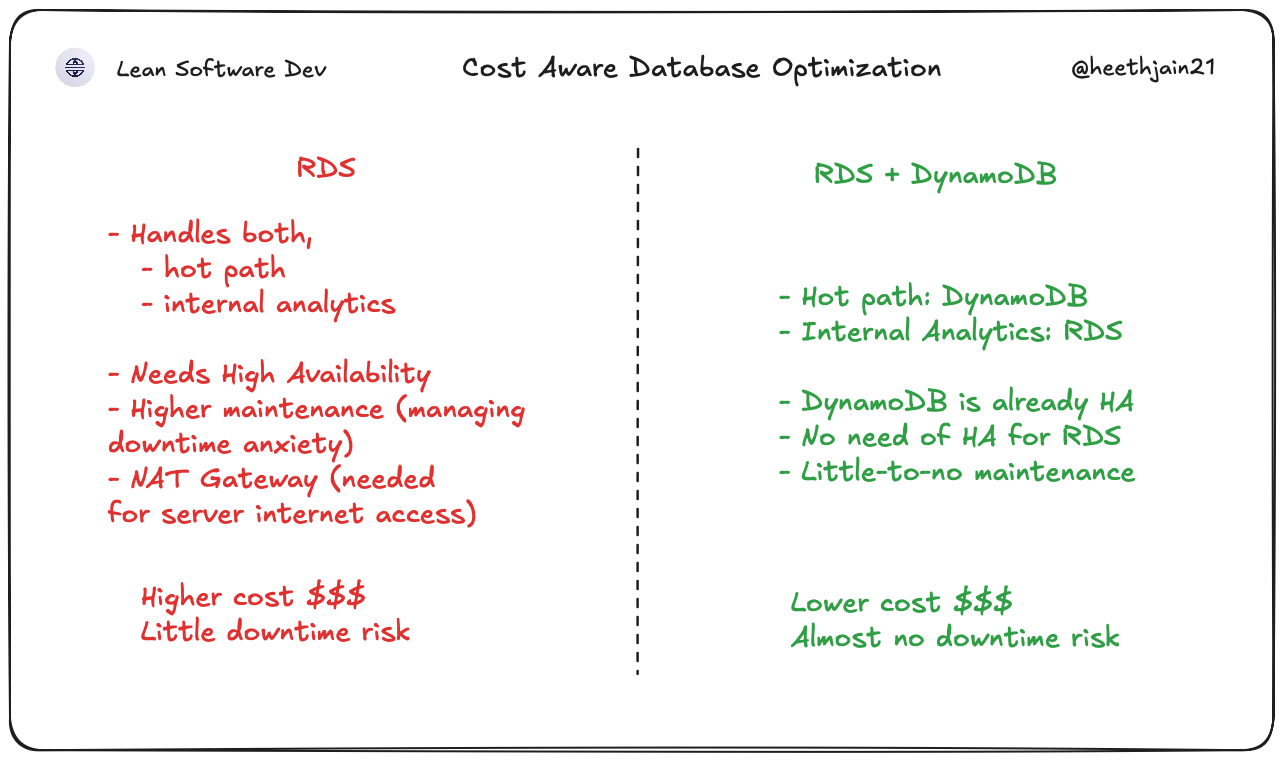
The client's support and business teams needed SQL reporting on webhook logs. But the same database would also be used for handling delivery for webhooks (requires almost no downtime). One bad analytics query or a reporting spike could slow down or break live webhook forwarding which customers actually depended on. Increasing RDS resiliency meant using adding more AZs and needing NAT Gateway (expensive) in multi AZs for the server (i.e more costs).
Constraints
- Delivery path had stricter uptime requirements than analytics queries.
- Support and business teams still needed SQL-friendly reporting in Metabase.
- Infra choices had to stay cost-aware at projected webhook volume.
Solution
-
Kept operational routing data in DynamoDB for high-availability webhook processing. It just answers the question: where does this webhook go?
-
Added an SQS batch queue and Lambda writer to push webhook logs into PostgreSQL (RDS) in batches.
-
If RDS has an issue, webhooks keep forwarding. The paths don't touch each other.
-
Accepted a slightly more complex topology to isolate webhook delivery from analytics workload patterns while also saving costs on NAT Gateways.
Outcome
- Webhook forwarding is isolated and reliable.
- Gave business/support teams near-real-time reporting (about one-minute batch latency).
- Produced explicit cost visibility with monthly service estimates for ops planning.
- Created clear boundaries so delivery and reporting can be tuned independently.
Trade-off
In hindsight, an early-stage version could start with a single database and evolve later. However, this also costs more due to the need for High availablility for RDS and also requires NAT Gateways (multi-AZ) (since server needs to be in VPC, and thus loses internet connection). For this project's reliability requirements + cost consideration, I chose separation sooner. Cost stays predictable. and no redesign needed as traffic grows.
Stack
- AWS DynamoDB
- AWS SQS
- AWS Lambda
- AWS RDS (PostgreSQL)
- Metabase