Dual Primary Keys in DB Design
Space efficient joins with safer public identifiers
Problem
The client's event tracking system needed to be built which would also handle scale several years down the line. Using UUIDs everywhere meant killing join performance on high volume tables. But using auto-increment integers for IDs visible on the client side meant anyone could enumerate customer IDs and guess activity patterns; a security risk the client couldn't ship with.
Constraints
- Event ingestion and joins needed compact indexes to keep write/read paths efficient.
- Public identifiers in URLs and auth adjacent flows needed to be non enumerable.
- We wanted to avoid a future migration from "simple now" key choices that usually become painful later.
- The pattern needed to stay straightforward for app developers across APIs, jobs, and queries.
Solution
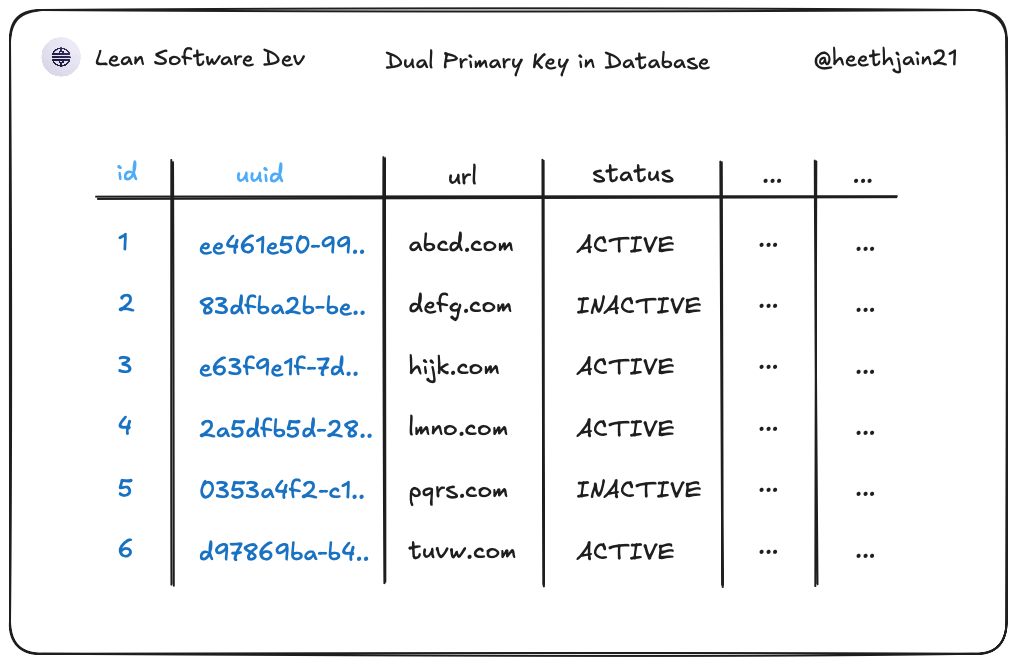
- Used integer primary keys (
id) for internal tables, joins, and clustered index efficiency. - Added uuid public keys (
uuid) for all externally visible identifiers. - Standardized backend behavior: internal services join on
id, external APIs only accept/returnuuid. - Chose this split deliberately over "uuid everywhere" (costlier joins/storage) and "integer everywhere" (enumeration risk).
Outcome
- Shipped a schema that stays performant on high write event tables while keeping external identifiers privacy safe.
- Removed ID enumeration as an easy attack surface for public and token adjacent flows.
- Gave the team a consistent convention that reduced accidental key misuse across handlers and jobs.
- Avoided a risky "keys migration" class of rewrite by getting the pattern right in v1 architecture.
Stack
- Node.js (express)
- PlanetScale (MySQL)