Horizontal Scaling with Cron Jobs
Eliminating duplicate cron execution in autoscaled backends
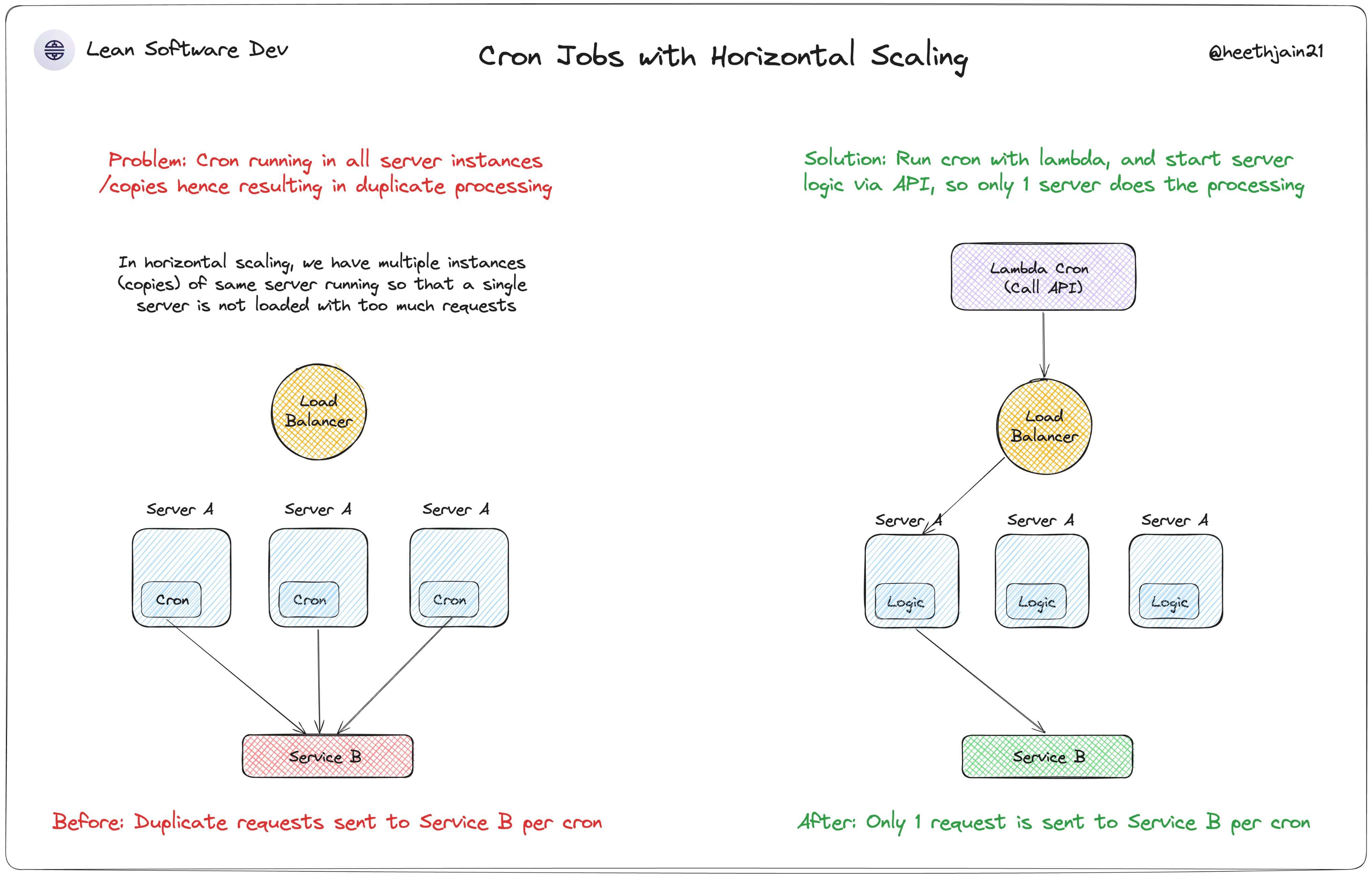
Problem
As the client's server scales to multiple backend instances behind a load balancer, scheduled jobs would start running multiple times, thus creating a duplication issue. The in process cron library wouldn't know it was running on multiple machines, and every autoscale event would make the problem worse.
Constraints
- The app ran multiple instances behind a load balancer, so in process cron was unsafe.
- Scheduled work needed exactly-once triggering semantics per interval.
- We wanted to avoid leader election, lock orchestration, or introducing a permanent "master" service.
- The solution needed to be simple to operate with low ongoing maintenance overhead.
Solution
- Moved scheduling outside app instances using AWS EventBridge and AWS Lambda.
- Triggered a backend API endpoint from Lambda through the load balancer.
- Kept the endpoint lightweight: validate trigger, enqueue async internal processing, return quickly.
- Chose this over in app leader patterns to remove distributed coordination complexity from the product codebase.
Outcome
- Removed duplicate scheduled-job execution in the autoscaled environment.
- Prevented a class of repeated side effect incidents caused by multi instance cron overlap.
- Kept the stack lean with managed scheduler/trigger components and no custom election logic.
- Created a repeatable pattern for future scheduled workflows without increasing app complexity.
Stack
- Node.js (express)
- AWS EventBridge
- AWS Lambda
- AWS ALB
- AWS Fargate